CUDA&cuDNN環境構築のためのバージョン確認方法(Windows)
はじめに
深層学習技術を用いたソフトを使用する際に、CUDAとcuDNNの導入が必要なケースも増えてきました。 ダウンロードやインストールもそこそこ難易度が高いですが、インストールできたとしても動かないことがよくあります。よくある問題の1つは、バージョンの相性問題です。
そこでこの記事では、各ツールのバージョンを確認する方法を記載します。(※各ツールのインストール方法は扱いません)
バージョン合わせの重要性
ハード側は、GPU ドライバーのバージョンによって、動作するCUDAバージョンが決まり1、そのCUDAバージョンによって動作するcuDNNのバージョンが決まり2ます。
この条件を満たした上でさらに、ソフト側がサポートするバージョンであること、が求められます。
※ソフト側からすれば使いたいのはcuDNNやCUDAなので、以下のように逆の流れで決まるわけですね。
- ソフトはcuDNNのバージョンXに対応。
- cuDNNのバージョンXに対応するCUDAはバージョンY。
- CUDAのバージョンYに対応するGPUドライバーはバージョンZ。
特に古いバージョン向けのソフトを新しいバージョンの環境では動かせない(下位互換性がない)ことがあるため、バージョン合わせが重要になります。
作業情報
筆者環境
- OS: Windows 10 Home 64bit
- GPU: NVIDIA GeForce RTX 3060 Ti
- NVIDIA ドライバー、CUDA Toolkit、cuDNN を導入済み
確認内容
手順
GPUの型番
【GUIで確認する】
Ctrlキー +Shiftキー +Escキーを押して、タスクマネージャーを開きます。簡易表示になっている場合は、左下の「詳細」をクリックします。
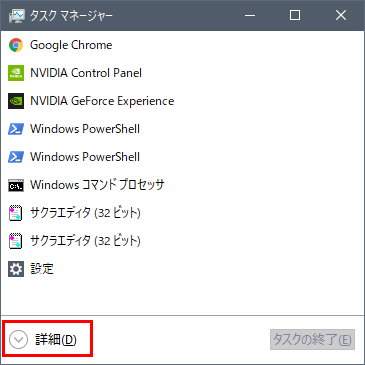
「パフォーマンス」タブを開き、左側のリストの一番下の項目にGPUと書かれたものがある(はず)なので、クリックします。
- 右上に表示されているのがGPUの型番です。

【CLIで確認する】
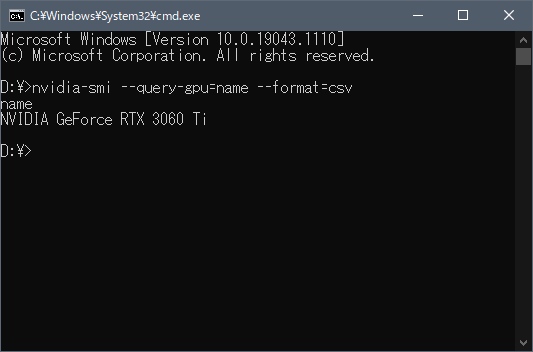
NVIDIA ドライバーのバージョン
【GUIで確認する】
Winキー +Sキー を押し、検索ボックスに「NVIDIA Control Panel」のように入力し、NVIDIA コントロール パネルを起動します。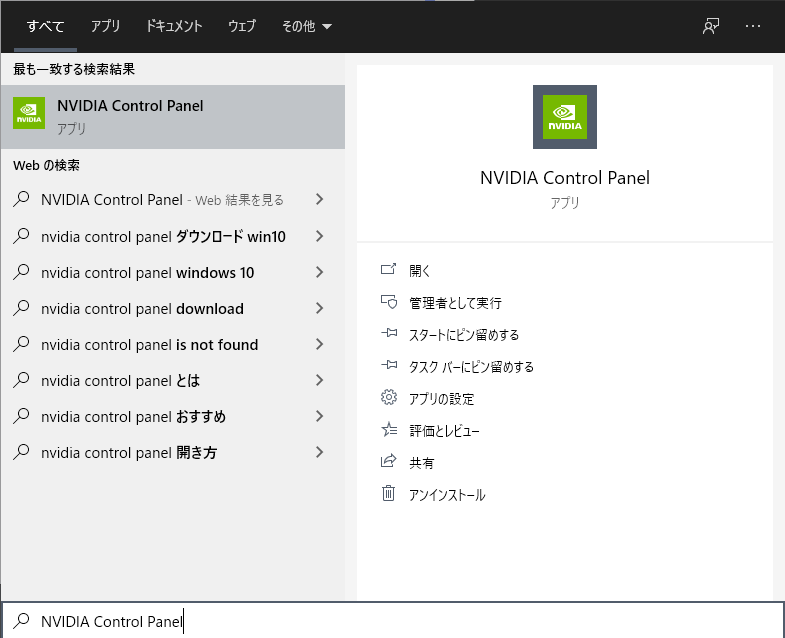
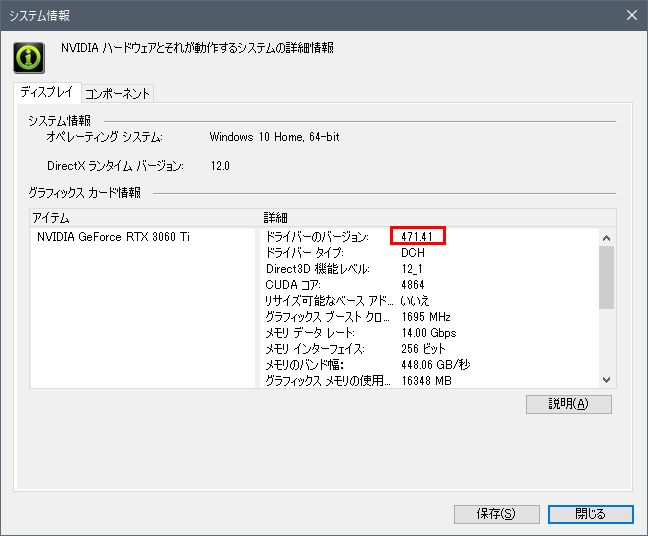
メニューバーの「ヘルプ」 > 「システム情報」をクリックします。
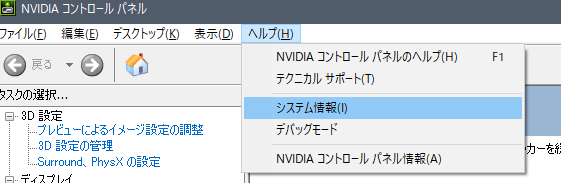
表示されたシステム情報の、詳細欄の「ドライバーのバージョン」で表示されているのがインストールされているNVIDIA ドライバーのバージョンです。
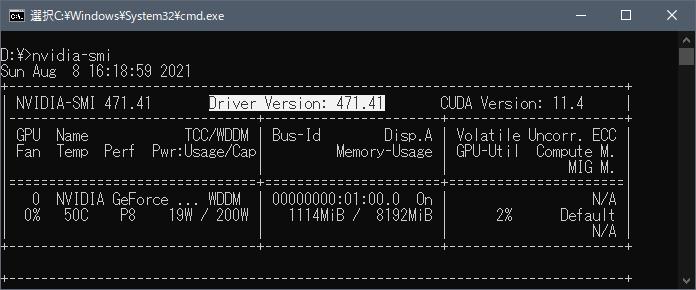
【CLIで確認する】
CUDA Toolkit のバージョン
【CLIで確認する】
コマンドプロンプトを開き、以下を実行します。
nvcc -VCuda compilation tools,のあとに表示されているバージョンがCUDA Toolkit のバージョンです。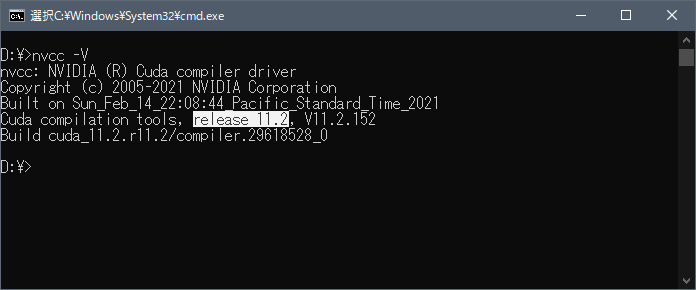
- 見つからないと表示された場合は、未導入か、CUDA Toolkitがうまくインストールできていない可能性があります。
cuDNN のバージョン
【CLIで確認する】
コマンドプロンプトを開き、以下を実行します。
where cudnn64_*.dllOSが認識しているcuDNNが表示されます。

- 見つからないと表示された場合は未導入か、ファイルの配置ができていても、PATHが通っていない場合があります。
表示されているパスをメモ帳などにコピーし、
bin\以降のパスをinclude\cudnn.hに置き換えます。#例:置き換え前 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\bin\cudnn64_8.dll #例:置き換え後 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\include\cudnn.h作成したパスに向けて以下のようなfindコマンドで
#defineを検索します。find "#define" "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\include\cudnn.h"以下のような、結果が返ってきていれば、上から順番に数字を並べるとcuDNNのバージョンになります。
#define CUDNN_MAJOR 8 #define CUDNN_MINOR 1 #define CUDNN_PATCHLEVEL 1- この場合は、バージョン8.1.1です。
上記のような結果が返ってこなければ、最後の
cudnn.hをcudnn_version.hに変更して再試行します。find "#define" "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\include\cudnn_version.h"
- 筆者環境では、
cudnn_version.hに変更して確認することができました。
- 筆者環境では、
確認手順は以上です。
参考サイト
- NVIDIA 公式ドキュメント
- NVCC :: CUDA Toolkit Documentation https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/#nvcc-command-options
- NVIDIA System Management Interface | NVIDIA Developer https://developer.nvidia.com/nvidia-system-management-interface
- [Linux / Ubuntu] GPUの種類(フルネーム)を確認する【名前が途切れる人向け】 - Qiita https://qiita.com/tik26/items/b3210cb945493345e8f7
- 環境構築したCUDA及びcuDNNのバージョンを確認する方法(Windows) | 技術的特異点 http://tecsingularity.com/cuda/version_conf/
-
Release Notes :: CUDA Toolkit Documentation https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions↩
-
Support Matrix :: NVIDIA Deep Learning cuDNN Documentation https://docs.nvidia.com/deeplearning/cudnn/support-matrix/index.html↩
WSL2のストレージを移動させる
はじめに
WSL2でDockerを使っていると、WSL2のストレージ容量がどんどん膨らみ、 Cドライブの残り容量が逼迫するようになったので、WSL2のストレージ(仮想HDD)をDドライブに移動させた。備忘も兼ねてその手順を記載する。
作業情報
筆者環境
- Windows 11 Home 64bit
- WSL2 をセットアップ済み
- Ubuntu-20.04を使用
- Docker Desktop for Windows をセットアップ済み
- WSL2をバックエンドに動作
作業内容
- WSL2のディストリビューションのストレージをCドライブのデフォルトの場所から、Dドライブの任意の場所に移動させる。
- 記載例では以下を実施。
- 移動させるディストリビューション名
- Ubuntu-20.04
- docker-desktop-data
- docker-desktop
- 移動先ディレクトリ
D:\WSL\
- 移動させるディストリビューション名
作業の流れ
- ディストリビューション名の確認、移動先フォルダの作成
- Docker DesktopとWSL2の停止
- ディストリビューションのエクスポート
- 現行ディストリビューションの削除
- ディストリビューションのインポート
- デフォルトのログインユーザーの変更
- 動作確認
- 撤収作業
手順
ディストリビューション名の確認、移動先フォルダの作成
ストレージを移動させたいディストリビューション名を確認する。
wsl -l で確認が可能。
移設先と、エクスポートしたファイル置き場が必要になるので、必要に応じてフォルダ作成などをする。
今回は例として、以下のような場合のコマンドを記載する。
D:\WSL\にファイルをエクスポートするD:\WSL\[ディストリビューション名]\にストレージを移動させる
以下、特に記載のない限り、PowerShellのコードを記載。
#WSL2のディストリビューション名の確認 wsl -l #移動先のフォルダを作成 mkdir D:\WSL #ディストリビューション名でフォルダを作成 cd D:\WSL mkdir Ubuntu-20.04 mkdir docker-desktop-data mkdir docker-desktop #結果確認 ls
※フォルダ作成はエクスプローラーなどでもOK
【確認】
- 移動先のフォルダが作成されていること
Docker DesktopとWSL2の停止
タスクトレイのDockerのアイコンを右クリックして、「Quit Docker Desktop」をクリックして、Docker Desktopを停止させる。
その後、wsl --shutdownでWSL2を停止させる。
wsl -l -vですべてのディストリビューションがSTOPPEDになっていることを確認する。
#WSL2シャットダウン wsl --shutdown #WSL2の稼働状況確認 wsl -l -v
【確認】
- すべてのディストリビューションのSTATEが、
Stoppedになっていること
ディストリビューションのエクスポート
wsl --export <Distribution Name> <FileName>でディストリビューションのエクスポートを行う。
tar形式で出力されるため、出力先パスも.tarにしている。
wsl --export Ubuntu-20.04 D:\WSL\ubuntu.tar wsl --export docker-desktop-data D:\WSL\dkdata.tar wsl --export docker-desktop D:\WSL\dk.tar
【確認】
- tarファイルが出力されていること
ディストリビューションの削除
wsl --unregister <Distoribution Name>でディストリビューションを削除する。
このコマンドを実行すると既存のストレージは削除されるため、前手順で、tarファイルがエクスポートできているかを確認してから実施する。
wsl --unregister Ubuntu-20.04 wsl --unregister docker-desktop-data wsl --unregister docker-desktop
ディストリビューションのインポート
wsl --import <Distribution Name> <InstallLocation> <FileName>でディストリビューションをインポートする。
今回はWSL2のインポートなので、忘れずに --version 2 を指定する。
wsl --import Ubuntu-20.04 D:\WSL\Ubuntu-20.04 D:\WSL\ubuntu.tar --version 2 wsl --import docker-desktop-data D:\WSL\docker-desktop-data D:\WSL\dkdata.tar --version 2 wsl --import docker-desktop D:\WSL\docker-desktop D:\WSL\dk.tar --version 2
#インポートできているか確認 wsl -l
【確認】
- インポートしたディストリビューション名が表示されていること
デフォルトのログインユーザーの変更
この方法で作成したディストリビューションはrootユーザーでのログインとなってしまうので、以下のコマンドでデフォルトのログインユーザーを変更する。
<DistributionName> config --default-user <Username>
Ubuntu-20.04 config --default-user ユーザー名
動作確認
WSL2と、Docker Desktopを起動してうまく動くか確認する。
撤収作業
エクスポートしたtarファイルはそのまま残るため、不要な場合は手動で削除する。
参考サイト
WSL の基本的なコマンド | Microsoft Docs https://docs.microsoft.com/ja-jp/windows/wsl/basic-commands
WSL2のLinuxおよびDockerイメージ格納先を任意のディレクトリに移動する - SIS Lab https://www.meganii.com/blog/2021/07/11/move-the-destination-of-wsl2-linux-and-docker-image-container-to-another-directory/
WSL2のストレージを移動する - (名称未定) https://okutom.hatenablog.com/entry/2020/12/28/172725
PowerShellでExcelの値をRangeで取得して取り出す(複数セルの場合)
はじめに
PowerShellでExcelのセルの値を取得する場合、Range("A1:D1")のように複数セルを指定することができます。
代入時はRange()で指定した範囲すべてが代入値に置換されるのでわかりやすくなっていましたが、取得の場合はひと工夫が必要になります。
そこで今回は、複数セルを範囲指定した場合の値の取り出し方について記載します。
環境
- Windows 10 Home 64bit
- Windows PowerShell 5.1.19041.906
- Microsoft Excel 2013
【結論】取得方法
初めに結論だけ記載します。
結果は配列で取得が可能です。このとき、Range().Textではなく、Range()までにするのがポイントです。
その後、取得したオブジェクトに添字をつけて.Textで取得できます。
PS D:\> $readData = $sheet.Range("A1:B20")
PS D:\> $readData[1].Text
$A$1
PS D:\>
準備
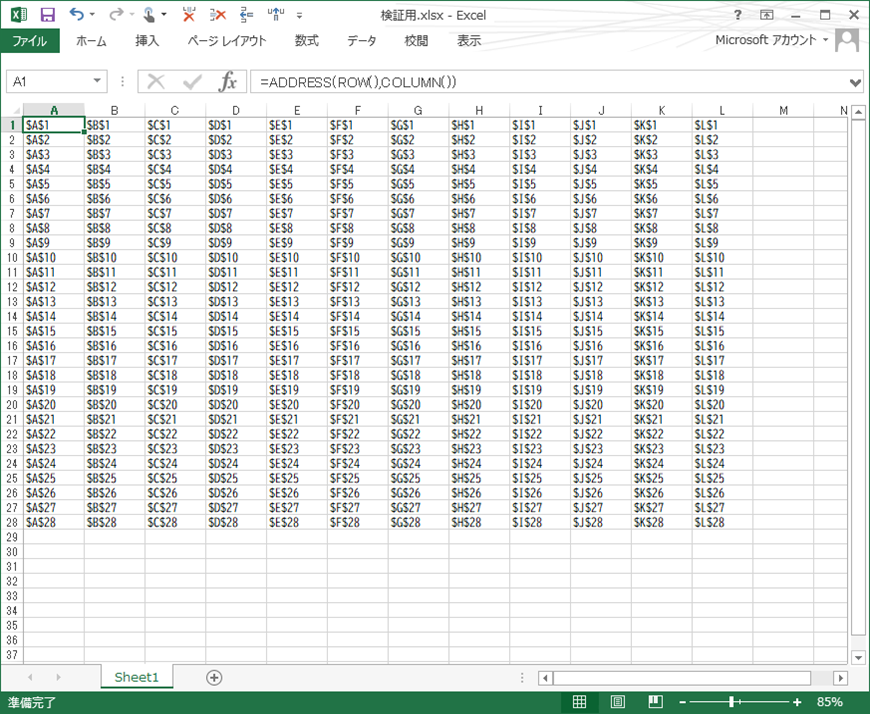
今回の検証には以下のデータを使用。
ソースコードは、PowerShellでExcelを扱う場合、一般的だと思われるものを作成。
#------------------------------------------------------------------------ #【設定】Excelファイルのパス $bookPath = "D:\workspace\powershell\検証用.xlsx" #【設定】対象のシート名 $sheetName = "Sheet1" #------------------------------------------------------------------------ #Excel起動 $excel = New-Object -ComObject Excel.Application #可視化設定(通常利用時はFalse。挙動確認の際はTrueだとわかりやすい。) #$excel.Visible = $False $excel.Visible = $True #アラート無効化 $excel.DisplayAlerts = $False #Excelファイル(ブック)を開く $book = $excel.Workbooks.Open($bookPath) #処理対象のシートを取得 $sheet = $book.Sheets($sheetName) #------------ # ここでいろいろ取得したりいろいろする。 #------------ #検証終了時は以下を実行 #------------------------------------------------------------------------ #Excel終了 $excel.Quit() #プロセス解放 $excel = $Null [GC]::collect() #------------------------------------------------------------------------
検証
1セルの値を取得する
$readData = $sheet.Range("A1").Text $readData
実行結果
PS D:\> $readData = $sheet.Range("A1").Text
PS D:\> $readData
$A$1
PS D:\>
→取得できる
同じように2セル以上の値を取得してみる(失敗)
$readData = $sheet.Range("A1:B20").Text $readData
実行結果
PS D:\> $readData = $sheet.Range("A1:B20").Text
PS D:\> $readData
PS D:\>
→何も取得できない
結果が配列であることを考慮して取得(成功)
$readData = $sheet.Range("A1:B20") $readData[1].Text
実行結果
PS D:\> $readData = $sheet.Range("A1:B20")
PS D:\> $readData[1].Text
$A$1
PS D:\>
※ちなみに、添字[0]はエラーになるようです。
PS D:\> $readData[0].Text
HRESULT からの例外:0x800A03EC
発生場所 行:1 文字:1
+ $readData[0].Text
+ ~~~~~~~~~~~~~~~~~
+ CategoryInfo : OperationStopped: (:) [], COMException
+ FullyQualifiedErrorId : System.Runtime.InteropServices.COMException
ループを回す際などには配慮が必要となりそうです。
取得した値を順番に取り出すには
#取得値を順次出力 $readData | % { $_.Text }
- パイプ「
|」で取得したオブジェクトを渡す ForEach-Objectの別表記「%{ }」で、受け取ったオブジェクトを1つずつ取り出して処理する- 「
$_」はパイプで受け取ったオブジェクトを指す変数
実行結果
PS D:\> $readData | % { $_.Text }
$A$1
$B$1
$A$2
$B$2
$A$3
$B$3
$A$4
$B$4
$A$5
$B$5
$A$6
$B$6
$A$7
$B$7
$A$8
$B$8
$A$9
$B$9
$A$10
$B$10
$A$11
$B$11
$A$12
$B$12
$A$13
$B$13
$A$14
$B$14
$A$15
$B$15
$A$16
$B$16
$A$17
$B$17
$A$18
$B$18
$A$19
$B$19
$A$20
$B$20
PS D:\>
無事取得できました。
おわりに
これだけだと、何の役に立つのかというところですが、Get-ChildItem -File -Filter *.xlsxやAdd-Contentなどと組み合わせて、特定ディレクトリにあるExcelファイルの特定の範囲の値を取得して、CSVに整形して出力するなど、応用の幅は広いと思います。
また、行と列で指定するCells.Item(r,c)は1セルずつのため、複雑な制御をしない場合は、Range()のほうが楽なのではないでしょうか。
感想など
- 自動処理が欲しいと思うぐらいExcelを作っていかないといけない現状をどうにかしたい。
- PowerShellでExcelを操作する強みは、ブック間を跨いだり、外部ファイルを取り込むなど、Excelの外の機能とつないでいろいろできるところにあると思います。
参考
- PowerShell で Excel をどうのこうのすることに興味を持ってくれると嬉しい - Qiita https://qiita.com/miyamiya/items/161372111b68bad0744a
- PowerShell を使ってExcel を操作する - メモ.org https://maskaw.hatenablog.com/entry/2018/09/22/183053
PowerShellのOut-GridViewの列名重複を回避する
はじめに
Windows PowerShellには、Out-GridView というコマンドがあります。
これは、行と列を持つ内容をGUIで表示できる機能で、 Import-Csv コマンドと組み合わせて、CSVファイルのデータを手軽にGUIで閲覧することができます。
Import-Csv [csvファイル] -Encoding [エンコード] | Out-GridView
しかし、Import-Csv する際に、列名の重複は許されません。
同名の列名がある場合、Out-GridView するところまでたどり着かずエラーとなってしまいます。1
とりあえずCSVを閲覧するのに便利なのが、Out-GridView コマンドです。 そこで、エラー時に連番をヘッダーにして開き直すスクリプトを作成しました。
環境
Windows 10 Home 64bit
Windows PowerShell 5.1.19041.906
※
Out-GridViewでWindowsのGUIを使用するため、マルチプラットフォーム版のPowerShell 7などでは動きません。
エラー時に列名を自動付与するPowerShellスクリプト
#$args = ドラッグ&ドロップされた要素 #拡張子の指定(大文字小文字の区別なし。.を含む) $extension = ".csv" #エンコードの指定(Default(Shift_JIS)、またはUTF8(UTF-8)) $encoding = "Default" #ドラッグ&ドロップされた要素を1つずつ取り出して処理 foreach ($arg in $args) { #指定の拡張子の場合のみ処理 if ((Get-Item $arg).Extension -eq $extension) { try { Import-Csv $arg -Encoding $encoding | Out-GridView } #エラー時の処理 catch { #1行目の内容の個数を取得 $col_count = (((Get-Content $arg -Encoding $encoding)[1]).Split(",").Count) #取得した個数分の列名をつけて表示 Import-Csv $arg -Encoding $encoding -Header @(1..$col_count) | Out-GridView } } } exit
何らかのエラーが発生したとき、 CSVの2行目[添字1]の内容から項目数(列数)を取得して、その連番をヘッダーに指定します。
やっつけ処理なので、ちゃんとやるなら全行の項目数を確認して最大値を取得する必要がありそうです。 今回はCSVであることが前提なので実装していません。
もし、列名重複エラーのみをcatchしたい場合は、catchの最初を以下のように変更します。
catch [System.Management.Automation.ExtendedTypeSystemException] {
今回掲載しているのは、ファイルをドラッグアンドドロップすることで動くスクリプトです。 スクリプトをps1ファイルとして保存したあと、ショートカットを作成して、 引数(プロパティ > リンク先)を修正すると、使用することができます。
powershell -ExecutionPolicy RemoteSigned -File [ps1ファイルパス]
上記PowerShellのドラッグアンドドロップについては、以下を参考にさせていただきました。
おわりに
最新バージョンのExcelでない場合、CSVファイルがUTF-8だと文字化けしてしまうのは、あるある話ですが、Out-GridViewでエンコードをUTF8にすることで、手軽に文字化けなく閲覧することができます。
とにかくファイルの中身を列を揃えて閲覧したいという場合に有効な手段の1つになると思います。 (ただし大量データだとものすごく重い、かつ列数は256までの模様)
感想など
Out-GridView自体はCSVでなくても開けるので、いろいろと使い道がありそう。- 表示したGUIを閉じる機能があれば知りたい(制御したい)。
- GUIまで使えてしまうPowerShellの魅力にどんどん惹かれてます。 今後もちょこちょこPowerShell記事を書くかもです。 ただあんまり依存するとシステム的にIEやめられない問題みたいになってしまいそうで怖い。
-
(2021/05/29 追記)列名重複エラーについて、当初「
Out-GridViewで表示する場合において、列名の重複は許されません。」と記載していましたが、再度調べたところImport-Csvする時点でエラーとなっていました。そのため、Out-GridViewコマンドの有無に関わらずImport-Csvコマンドを使用する際に、列名に重複があるとエラーになります。該当部分の記載内容を修正しました。↩
WindowsにOracle Databaseの環境構築 Part2 (SQL実行まで)
この記事では、Oracle DBわからん!な初心者の私が、WindowsにインストールしたOracle DBの起動・ユーザー作成、SQL実行の手順を記載します。
※とりあえず勉強用に動けばいい人向けです。
はじめに
WindowsでのOracle DB環境構築のPart2です。(最終回)
起動、ユーザー作成、SQL PlusでのSQL文の実行までを取り上げて終わります。
作業の流れ
- 起動・ログイン
- ユーザー作成
- SQL文実行
環境
目標
Windowsローカル環境にインストールしたOracle DBの起動、ユーザー作成、SQL文実行
1. 起動・ログイン
インストールが成功していれば、スタートメニューにOracle DBのフォルダが作成され、「SQL Plus」が実行できるようになっています。

Win + S を押して「cmd」と入力し、コマンドプロンプトを起動します。

コマンドプロンプトで以下実行します。
sqlplus sys/[インストール時に設定したパスワード] as sysdba
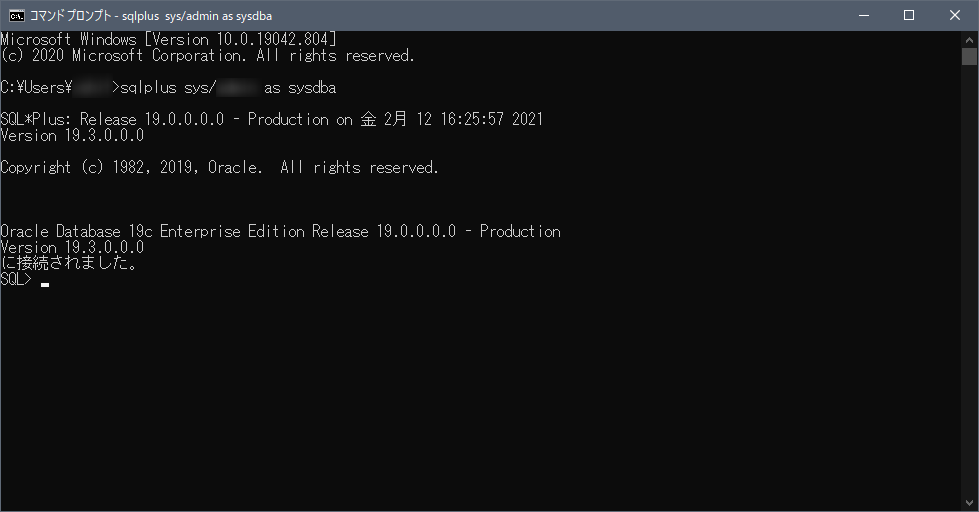
インストール後は、管理用アカウントしか作成されていないようなのでいったんこれでログインします。
2. ユーザー作成
ユーザー作成
SQL Plusにて、以下を実行します。
CREATE USER [ユーザー名] IDENTIFIED BY "[パスワード]" TEMPORARY TABLESPACE TEMP;

続いて接続の権限を付与します。
Oracle DBでは非常に細かい権限のコントロールができるようなのですが、とにかく動く環境を求めている初心者からすると、複雑で面倒でもあります。
ひとまず今回は最低限の権限を付与します。
以下を実行し、CONNECTロール(※ロール:権限をまとめたもの)とRESOURCEロールを付与します。 また、表領域(使用できる容量)を無制限に使えるようにしておきます。
GRANT CONNECT TO [ユーザー名]; GRANT RESOURCE TO [ユーザー名]; ALTER USER [ユーザー名] QUOTA UNLIMITED ON USERS;

これで作成したユーザーで、ログインや表作成が行えるようになりました。
以下を実行し、接続を閉じます。
exit
作成したユーザーでログイン
以下を実行し、作成したユーザーでログインします。
sqlplus [ユーザー名]/[パスワード]
ログインできたら、以下を入力し、ログインしているユーザー名が作成したユーザー名と同じであることを確認します。
SHOW USER

3. SQL文実行
それでは、表作成(CREATE TABLE)とデータ追加(INSERT)、抽出(SELECT)、削除(DELETE)を実行してみます。
実にてきとーな表を作ります。
CREATE TABLE TABLE_01 ( COLUMN1 NUMBER(4,0), COLUMN2 VARCHAR2(100), COLUMN3 VARCHAR2(100) );
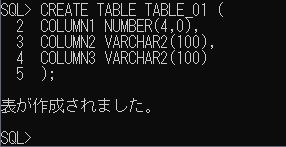
※VERCHAR2の数値はデフォルトでバイト単位になるようなので要注意です。(文字数で指定するときは、VARCHER2(100 CHAR)と指定するようです。)
何も設定が変わっていなければ、このテーブルは[ユーザー名と同名のスキーマ].[テーブル名]に作成されるはずです。
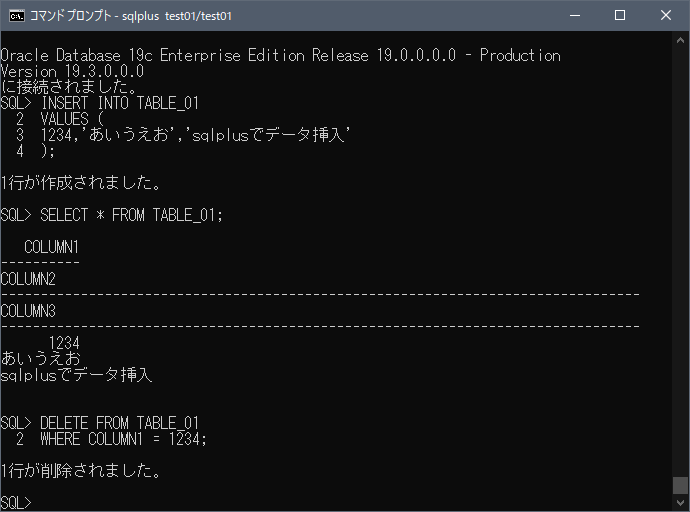
適当なデータを挿入します。
INSERT INTO TABLE_01 VALUES ( 1234,'あいうえお','sqlplusでデータ挿入' );
抽出してみます。
SELECT * FROM TABLE_01;
最後に削除します。
DELETE FROM TABLE_01 WHERE COLUMN1 = 1234;
おわりに
無事、SQL文をSQL Plusで実行することができました。
SQL Plusに限らず、ここで作成したユーザー名/パスワードで、GUIのツールからなどもログインすることができるようになります。
デフォルト設定であれば、接続設定は以下の通り。
- Host(ホスト名) → localhost
- Database(データベース) → orcl(※サービス名)
- Port(ポート番号) → 1521
また、今回権限は少なめに設定しているため、できない操作があればその都度権限を追加してみてください。
感想など
Oracleのスキーマ名とユーザー名が同じになる。という仕様を知らずに作業していたため、詰まったことがあった。スキーマを跨いで操作する場合は権限の設定も必要な模様。このあたりがOracle独特な気がするのは私だけだろうか。(PostgreSQLとMySQLしか触ったことなかった人の感想)
権限周りが初心者にとってむずい。とりあえず動かせる環境がほしいだけなのに!!ユーザー作成→接続権限がありません、表作成→権限が足りませんみたいなのを繰り返した。
面倒ならDBAアカウントで全部動かしても良かったが、前述の通りスキーマを分けるにはユーザーが必要そうだったので、結局ユーザーの権限設定も実施した。
そもそもDBAって何から調べる必要があった。インストール時にはパスワードしか指定していないので、ユーザー名は何でログインしたら良いのか分からず詰まった。
情熱大陸 #1140「サイバー技術開発集団 統括・登大遊」を観た
2020/02/07 放送分。
内容は、自治体テレワークシステムの開発。 詳しいシステムの話というよりかは、仕事のスタイルが内容の中心。 ※情熱大陸なので。
もうちょっと自由で正直になっていいのかもと思えた
情報処理技術者試験でもおなじみのIPAだが、その内部、というか研究室はもちろん初見。 もっとお堅いところかと思っていたが、わりと自由な雰囲気があっていいなあと思った。
登大遊さんが口にする「けしからん!」というワード。
「けしからん!」と思うことは多分日々の周りにいっぱいあって、 その「けしからん!」ことを、ちゃんと「けしからん!」と言って、 こうすれば、ああすればどうか、ところまでできるのがすごいなあと思った。
そして、映像を観た限りでは、登さんは楽しんでやっているように見えた。
そこでふと業務中の自身の姿が思い浮かび、頭抱えたい気分になっていた。
楽しく取り組むための工夫とか、本当に必要と思う物事があるのなら、 誰かを巻き込んで説明・説得してでも取り組もう。
靴下とシャツを脱いでプログラミングに快適な環境を作り出すのもその1つである。
苦しさと山歩き
本編の最後に山歩きのシーンがある。 山へ歩いて登る行為とプログラミングを重ね合わせて、 プログラミングのほうが比較的に楽に見えるのだとか。
システム開発(プログラミングも)にもいろいろ面倒なことがある。 (人それぞれだが、私にも心当たりはある。なんでこんな面倒なことを……と思うことが。)
山の頂上まで歩いて登るには(開発を完遂させるには)、 それなりの地道な作業の積み重ねということを思い知らせてくれる。
楽しみながらやったことで貢献したい
貢献したい欲がある人は特にそう思っているのではないだろうか。
私もその1人である。
登さんからは、それができていることが感じられたから、観ることができて良かったと思えた。
そうなるために、どうしたらいいか、へっぽこな私も考えてみた。 少なくとも楽しみながらやったことで貢献するには、「楽しみながら」やれていないと意味がない。
「楽しみながら」やるためには、やっぱりもっと自由で正直になること。 それが必要なのかなと、思いました。
TVerでの見逃し配信は2/14(日)の22:59まで。
ご本人の記事や、インタビュー記事も面白かったのでぜひ。
感想など
- なんとなく観始めたら、すごく元気をもらったので記事を書いてみました。何の宣伝でもありません。
WindowsにOracle Databaseの環境構築 Part1 (インストールまで)
この記事では、Oracle DBわからん!な初心者の私が、WindowsにOracle DBをインストールをするまでの手順を記載します。
※とりあえず勉強用に動けばいい人向けです。
はじめに
Oracle DBのSQL Plusを試したくなったため、ローカル環境にOracle DB環境を作ってみることにしました。 最終ゴールは、SQL Plusでログインして、SQL文を実行することです。 この記事(Part1)では、Oracle DBのインストールまでを取り上げます。
作業の流れ
- インストーラーのダウンロード
- インストール
環境
目標
Windowsローカル環境へのOracle DBのインストール
1. インストーラーのダウンロード
個人の学習や検証用途であれば「OTN開発者ライセンス」によって無料でOracle Databaseをインストールして使用することができます。
今回はこのライセンスでOracleの環境構築を行っていきます。
こちらからインストーラーをダウンロードします。
Oracle Database ソフトウェア・ダウンロード | Oracle Technology Network | Oracle 日本
Windows版を選択します。
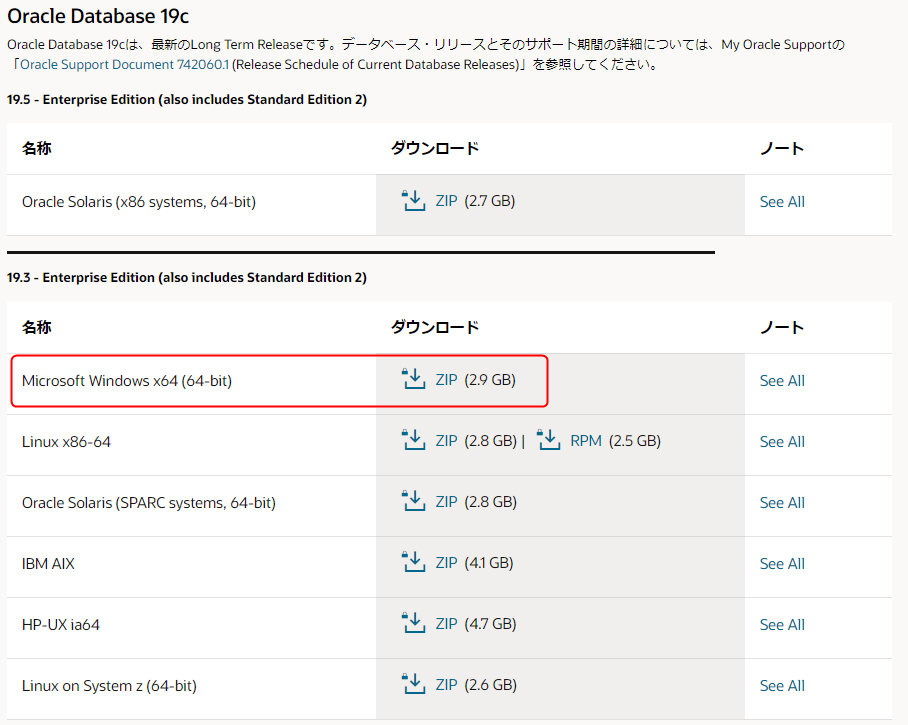
OTN開発者ライセンスに同意し、ダウンロードリンクをクリックします。
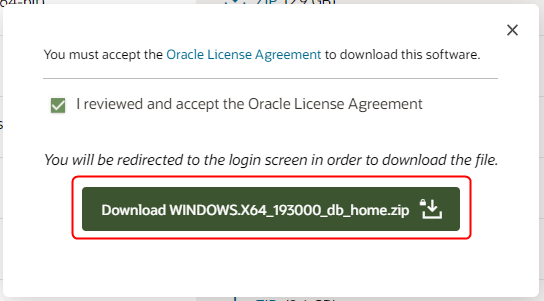
Oracleプロファイルでのログインを求められるので、ログインします。
ログインに成功するとダウンロードが開始されます。
※アカウント登録をしていない場合は、「Oracleプロファイルを作成する」から作成します。 個人の場合は、以下の通り入力すると良いでしょう。*1
- 部署・役職名 → 「個人」
- 会社名 → 自分の名前
- 勤務先電話番号 → 自分の電話番号
2. インストール
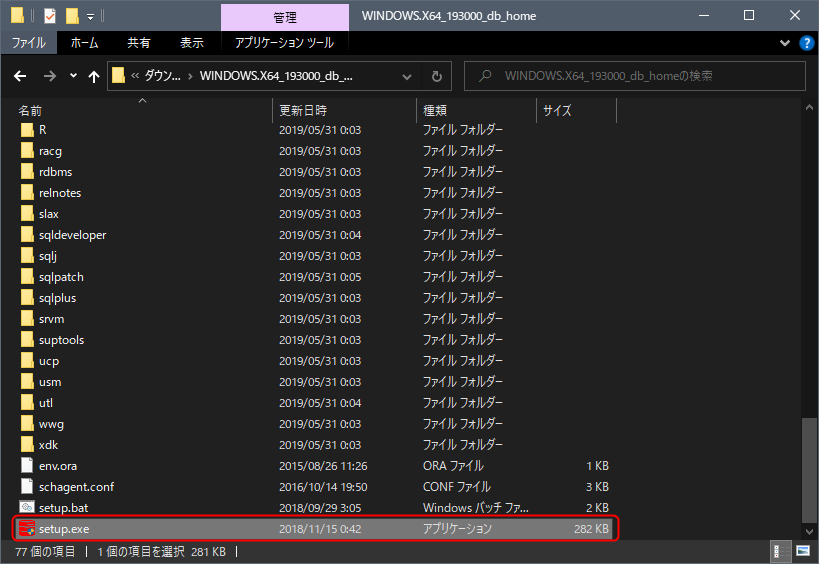
ダウンロードしたZIPファイルを解凍し、解凍したフォルダを任意の場所に移動させます。
※このデータはインストール後も使用され、移動させるのが難しくなるため
その後、setup.exeを起動します。
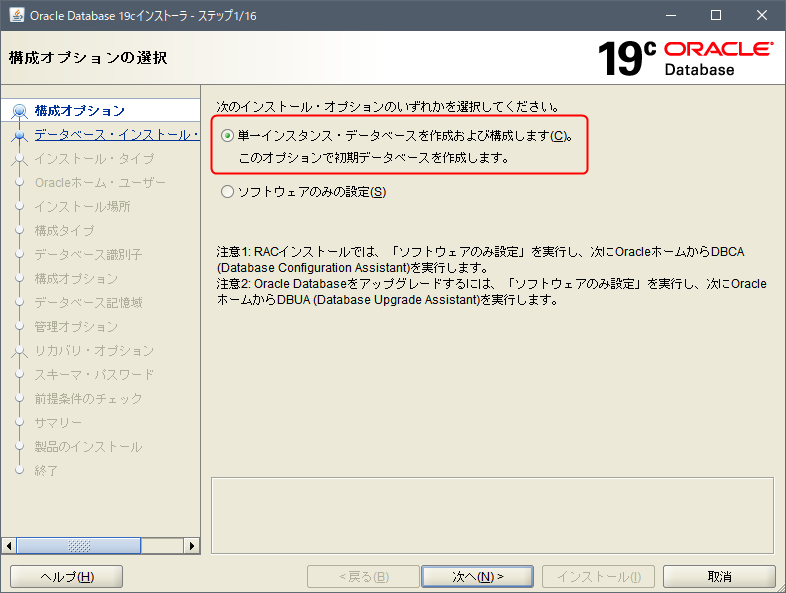
構成オプションの選択
単一インスタンス・データベース を選択します。
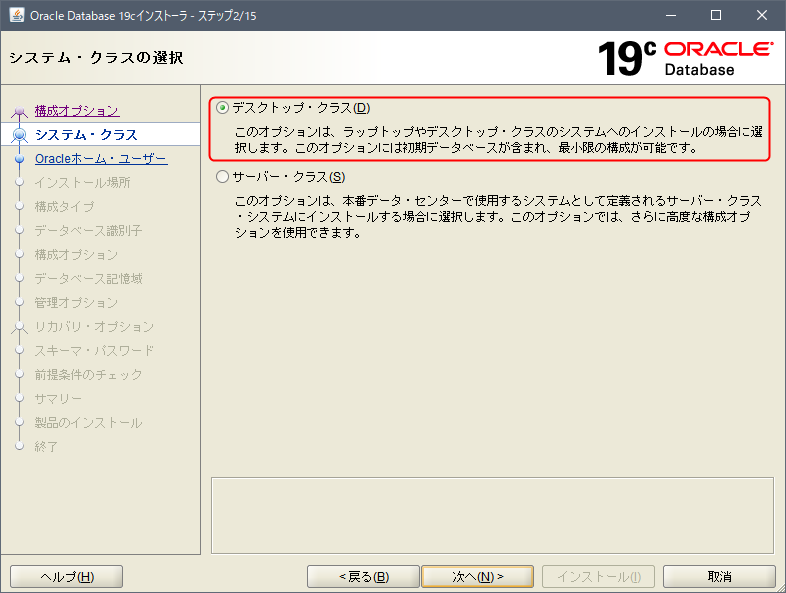
システム・クラスの選択
デスクトップ・クラス を選択します。
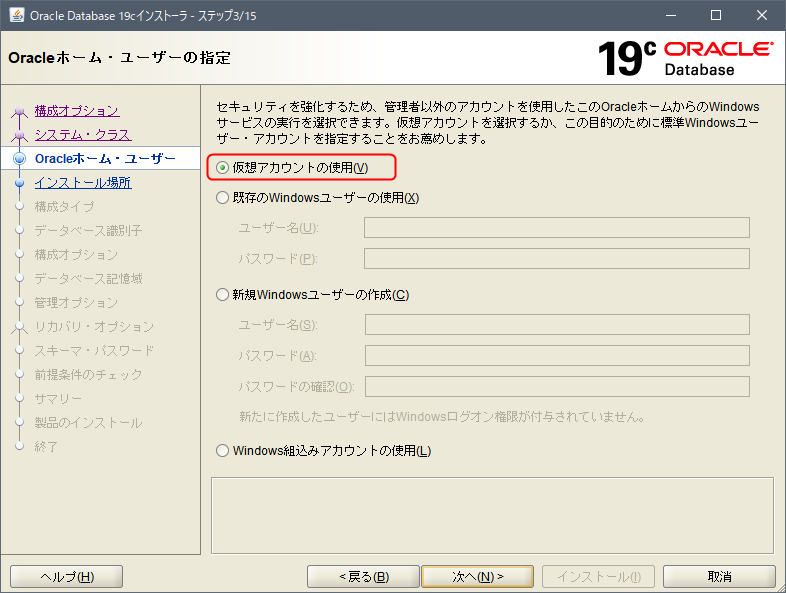
Oracleホーム・ユーザーの指定
仮想アカウントの使用 を選択します。
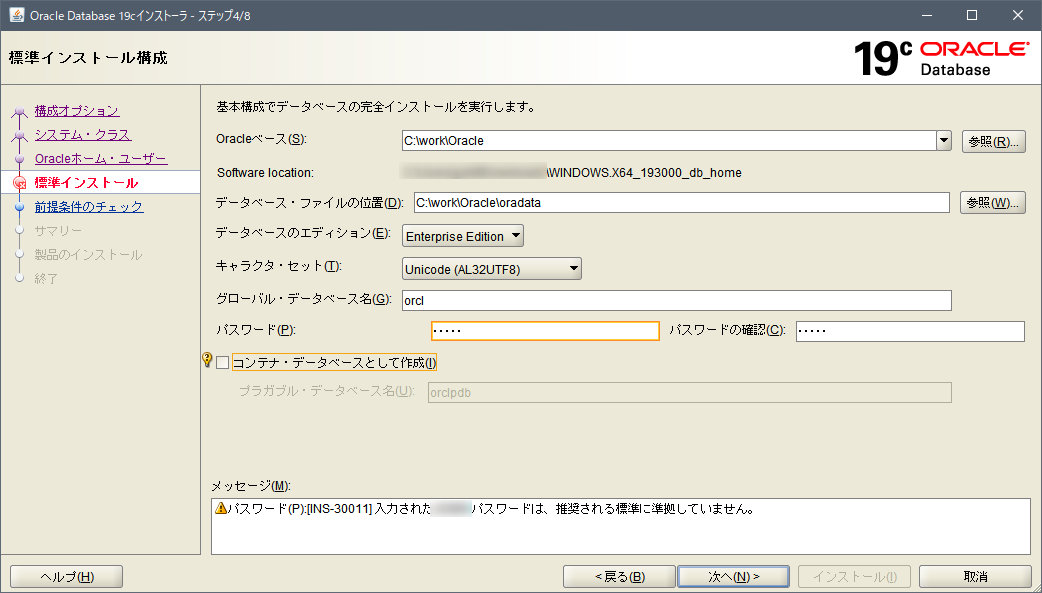
標準インストール構成
- キャラクタ・セット → 今回はデフォルトの「AL32UTF8」を選択しました。
※もし、Shift_JIS環境にしたい場合は、「JA16SJISTILDE」を選択します。 - パスワード → 設定します。
※貧弱なパスワードを入力すると警告が出ますが、今回の目的はお試しの環境構築なので続行します。 - コンテナ・データベースとして作成 → チェックを外します。
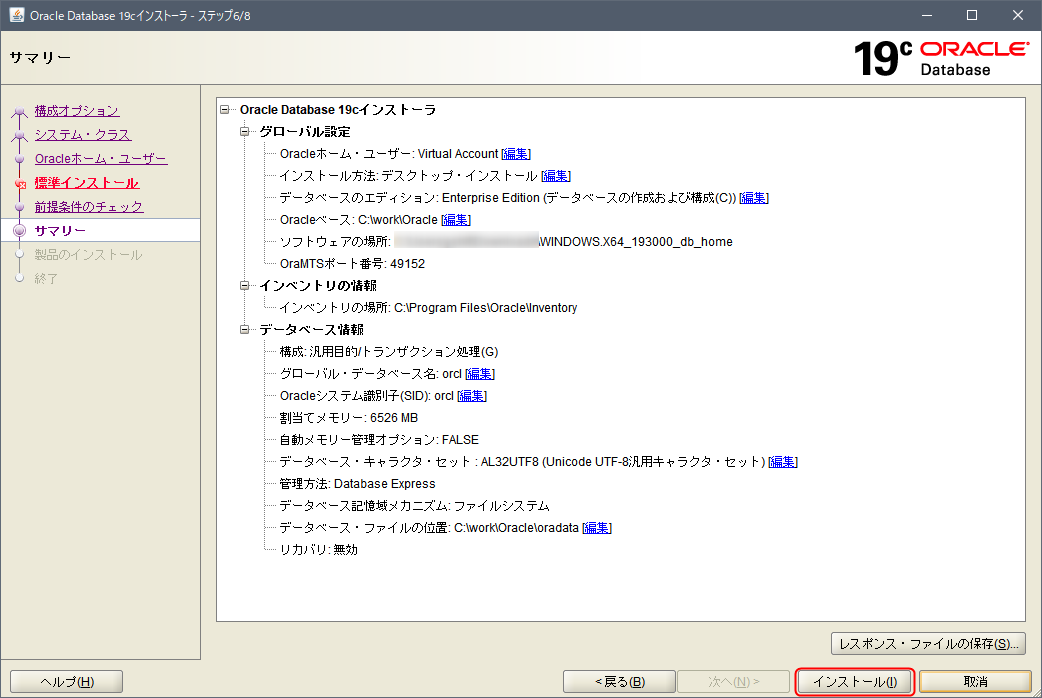
サマリー
内容を確認して、「インストール」ボタンでインストールを開始します。
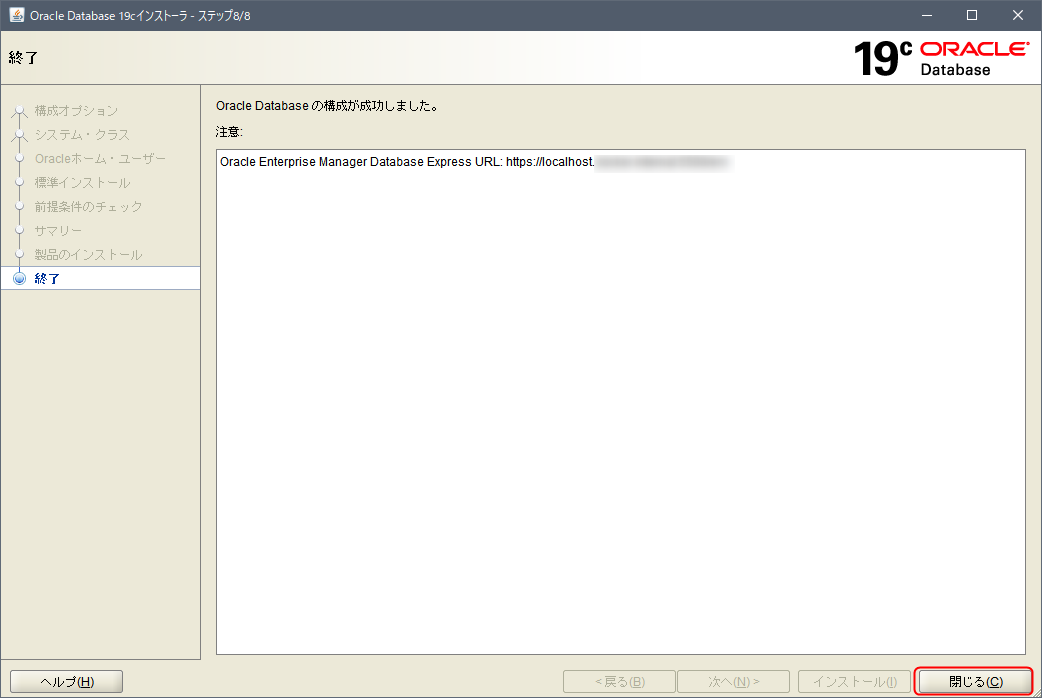
製品のインストール
そこそこ時間がかかるので待ちます。
完了したら、「閉じる」で終了します。
おわりに
Part2では、起動、ユーザー作成を実施します。